How to build a minimal deep learning web app from Fastai, Hugging Face Space, Github Page and Google Colab. A step-by-step guide for beginner
I build a minimal deep-learning web app to predict which thumbnail (Youtube video’s cover photo) is above or below the average click-through rate (CTR). All tools used are free!

You can try this app at oldfatboy.com. But it only works for my wife’s youtube channel, because the model is trained based on her channel’s dataset. As title mentioned, it is an MVP (Minimal Viable Product).
All steps are from the first two lectures of fast.ai’s practical deep learning for coders.
I highly recommend this practical course because it has a top-down mindset instead of traditional education’s down-top mindset. In another word, it teaches you the Whole Game instead of making you learn details for years before even trying to play the whole game.
All code can be found in my Github .
Big Picture
-
Step One: Prepare Data
-
Step Two: Train Model using Google Colab and Fast.ai
-
Step Three: Host model to Hugging Face Space
-
Step Four: Embed Hugging Face to a website built from Github Page
More detail of Step Two is on fast.ai lesson 1: Get Started
More details of Steps three and four can be found in Lesson 2: Deployment
Step One: Prepare Data
Use Youtube API to extract thumbnail data from my wife’s Youtube Channel. You need to replace api_key with your own API key which can be obtained from Youtube Data API key from here. Or you can use mine for now.
from googleapiclient.discovery import build
import pandas as pd
# Set up API client
api_key = "AIzaSyDRtin-ZzXXEK_BUzID4se9Esk8SxrtaHk"
youtube = build('youtube', 'v3', developerKey=api_key)
# Retrieve video data
channel_id = "UCN_hbfsIsYgj-PtGJT8aSAQ"
videos = []
next_page_token = None
request = youtube.search().list(
part='snippet',
channelId=channel_id,
maxResults=50, # Adjust the number of results per page as needed
pageToken=next_page_token
)
response = request.execute()
for item in response['items']:
video = {}
video['title'] = item['snippet']['title']
video['thumbnail'] = item['snippet']['thumbnails']['default']['url']
videos.append(video)
# Create a Pandas DataFrame from data
df = pd.DataFrame(videos)
df.head()
Download csv file of click-through rate from youtube studio (Youtube studio -> Analytics -> Advanced mode -> Export current view -> Comma-separated values (.csv)), because the Youtube API I used only allows access to public information. You can use another API to get access to creator’s data but this is a minimal product.

And upload the Table data.csv to the colab by drag and drop it in the left Files sections of colab.
# Read the CSV file into a Pandas DataFrame
df_ctr = pd.read_csv('Table data.csv')
df_ctr.head()
# Rename the df 'title' column to the same name of df_ctr whihch is 'Video title' for merging purposes
df = df.rename(columns={'title': 'Video title'})
# Merge the DataFrames based on the video title
df_merged = pd.merge(df, df_ctr[['Video title', 'Impressions click-through rate (%)']], on='Video title', how='left')
df_merged.head()
# Remove rows with NaN values
df_cleaned = df_merged.dropna()
df_cleaned.head()
| Video title | thumbnail | Impressions click-through rate (%) | |
|---|---|---|---|
| 2 | When you want to crochet and you have a baby | https://i.ytimg.com/vi/9ePFI7814Rc/default.jpg | 1.26 |
| 3 | Crochet Leaves | https://i.ytimg.com/vi/jx2ojGTX854/default.jpg | 4.57 |
| 4 | How to crochet pet collar | crochet tulips | B... | https://i.ytimg.com/vi/M5pbgRzZs6w/default.jpg | 4.39 |
| 5 | How to wrap flowers | crochet flower bouquet | https://i.ytimg.com/vi/rBFqpv-m6gc/default.jpg | 4.69 |
| 6 | Crochet for beginners: How to crochet scrunchi... | https://i.ytimg.com/vi/2hPsxSXwsf8/default.jpg | 3.11 |
# Export merged dataframe to csv file
df_merged.to_csv('thumbnail_ctr.csv', index=False)
You can find the exported file in the files section of the Colab as thumbnail_ctr.csv , and you can right-click on it (or click on the three dots next to it) and then download it for model training in the next step.
For blogging reasons, I converted this notebook to markdown with nbconvert. Therefore, markdown file can be rendered in my personal website hosted by GitHub Page.
You can need to download this notebook and upload it to the folder sections in colab for the below code to run. Details shows here. For some reason, nbconvert converts the output of pandas data frame (e.g. pd.head()) with html scripts. So I deleted the previous pd.head() output and only shows the last one by manually deleting the unwanted html script shown in the converted markdown file.
!jupyter nbconvert --to markdown Prepare_Data.ipynb
For deep learning training, you need to first change the Colab runtime to T4 GPU in the upper right corner.

Upload thumbnail_ctr.csv to Colab by drag and drop into the left Files section.
Step Two: Train Model using Google Colab and Fast.ai
import pandas as pd
# Read the CSV file into a Pandas DataFrame
df = pd.read_csv('thumbnail_ctr.csv')
# Delete NaN rows
df = df.dropna()
# Reindex the DataFrame
df = df.reset_index(drop=True)
df.head()
| Video title | thumbnail | Impressions click-through rate (%) | |
|---|---|---|---|
| 0 | When you want to crochet and you have a baby | https://i.ytimg.com/vi/9ePFI7814Rc/default.jpg | 1.26 |
| 1 | Crochet Leaves | https://i.ytimg.com/vi/jx2ojGTX854/default.jpg | 4.57 |
| 2 | How to crochet pet collar | crochet tulips | B... | https://i.ytimg.com/vi/M5pbgRzZs6w/default.jpg | 4.39 |
| 3 | How to wrap flowers | crochet flower bouquet | https://i.ytimg.com/vi/rBFqpv-m6gc/default.jpg | 4.69 |
| 4 | Crochet for beginners: How to crochet scrunchi... | https://i.ytimg.com/vi/2hPsxSXwsf8/default.jpg | 3.11 |
Below is a code example of using fast.ai library to download and show images from url.
from fastdownload import download_url
dest = 'thumbnail.jpg'
download_url(df['thumbnail'][2], dest, show_progress=False)
from fastai.vision.all import *
im = Image.open(dest)
im.to_thumb(256,256)

average_value = df['Impressions click-through rate (%)'].mean()
average_value
2.716734693877551
Separate the dataset into two categories: below average and above average.
below_average_df = df[df['Impressions click-through rate (%)'] < average_value]
above_average_df = df[df['Impressions click-through rate (%)'] >= average_value]
Download images from two categories into two different folders named above_average and below_average. Fast.ai library will use the folder’s name to label the images for training.
searches = 'below_average','above_average'
path = Path('thumbnail_cover_image')
for o in searches:
dest = (path/o)
dest.mkdir(exist_ok=True, parents=True)
if o == 'below average':
o_df = below_average_df
else:
o_df = above_average_df
download_images(dest, urls=o_df['thumbnail'])
resize_images(path/o, max_size=400, dest=path/o)
#Delete invalid image links
failed = verify_images(get_image_files(path))
failed.map(Path.unlink)
len(failed)
0
#Build fast.ai datablock for next step
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=[Resize(192, method='squish')]
).dataloaders(path, bs=32)
dls.show_batch(max_n=6)

Fine tune the existing Resnet model which has been pre-trained on millions of images. Fine tune method only train the last layer of the pre-trained model for the user’s dataset. Therefore, it saves time.
learn = vision_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(3)
/usr/local/lib/python3.10/dist-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/usr/local/lib/python3.10/dist-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet18_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet18_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /root/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth
100%|██████████| 44.7M/44.7M [00:00<00:00, 213MB/s]
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.438015 | 1.381293 | 0.500000 | 00:07 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.690220 | 1.451846 | 0.500000 | 00:01 |
| 1 | 1.592969 | 1.636217 | 0.500000 | 00:00 |
| 2 | 1.496134 | 1.836272 | 0.600000 | 00:00 |
Upload an example.jpg to text model
is_above_average,_,probs = learn.predict(PILImage.create('example.jpg'))
print(f"This is a: {is_above_average}.")
print(f"Probability its click-through rate above average: {probs[0]:.4f}")
This is a: above_average.
Probability its click-through rate above average: 0.8472
Export the fine-tuned model and download from the Files section of colab for next step.
learn.export('model.pkl')
Download and upload this notebook to Colab. Convert it to markdown using nbconvert for blogging reason.
!jupyter nbconvert --to markdown Train_Model.ipynb
Step Three: Host model to Hugging Face Space
Initial setup
#install gradio for GUI
!pip install gradio
#|default_exp app is marked for nbdev to convert code cells which are markded with #|export to .py file.
#|default_exp app
#|export
from fastai.vision.all import *
import gradio as gr
Upload example.jpg to Files section of google colab
im = PILImage.create('example.jpg')
im
Use trained model
#|export
learn = load_learner('model.pkl')
learn.predict(im)
('above_average', tensor(0), tensor([0.5759, 0.4241]))
#|export
categories = ('Above Average', 'Below Average')
def classify_image(img):
pred,idx,probs = learn.predict(img)
return dict(zip(categories, map(float,probs)))
classify_image(im)
{'Above Average': 0.575865626335144, 'Below Average': 0.42413434386253357}
Lauch Gradio app
#|export
image = gr.inputs.Image(shape=(192,192))
label = gr.outputs.Label()
examples = ['example.jpg', 'above_average.jpg', 'below_average.jpg']
intf = gr.Interface(fn=classify_image, inputs=image, outputs=label, examples=examples)
intf.launch(inline=False,share=True)
<ipython-input-22-ad0da62d8b7b>:2: GradioDeprecationWarning: Usage of gradio.inputs is deprecated, and will not be supported in the future, please import your component from gradio.components
image = gr.inputs.Image(shape=(192,192))
<ipython-input-22-ad0da62d8b7b>:2: GradioDeprecationWarning: `optional` parameter is deprecated, and it has no effect
image = gr.inputs.Image(shape=(192,192))
<ipython-input-22-ad0da62d8b7b>:3: GradioDeprecationWarning: Usage of gradio.outputs is deprecated, and will not be supported in the future, please import your components from gradio.components
label = gr.outputs.Label()
<ipython-input-22-ad0da62d8b7b>:3: GradioUnusedKwargWarning: You have unused kwarg parameters in Label, please remove them: {'type': 'auto'}
label = gr.outputs.Label()
Colab notebook detected. To show errors in colab notebook, set debug=True in launch()
Running on public URL: https://08ffbbcc32701578cd.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)
Export notebook cells marked with #|export to python script
!pip install nbdev
Export to google drive
Because I run this notebook in colab, I set up following code to save all files from colab session including exporting app.py from this notebook to a folder in my google drive. So I can download and upload to Hugging Face repo later.
from google.colab import drive
drive.mount('/content/gdrive')
Mounted at /content/gdrive
import os
import shutil
# Specify the source path (current Colab folder)
source_folder = '/content'
# Specify the destination path (Google Drive folder)
destination_folder = '/content/gdrive/My Drive/fastai/Lesson2/'
# Copy only files in the source folder (exclude subfolders)
for file_name in os.listdir(source_folder):
file_path = os.path.join(source_folder, file_name)
if os.path.isfile(file_path):
shutil.copy(file_path, destination_folder)
path = '/content/gdrive/My Drive/Colab Notebooks/' #default path where colad saves notebooks to your google drive
shutil.copy2(path+'app.ipynb', destination_folder) #change app.ipynb to the name of your colab notebook
'/content/gdrive/My Drive/fastai/Lesson2/app.ipynb'
import nbdev
nbdev.export.nb_export(destination_folder+'app.ipynb', destination_folder) #change app.ipynb to the name of your colab notebook
print('Export successful')
Export successful
Push to Hugging Face Space
Push the whole folder to your Hugging Face Space Repo by Git. You can see my Hugging Face Space repo example here.
You can find a detailed tutorial on this blog: Gradio + HuggingFace Spaces: A Tutorial.
Now the app is live and running in Hugging Face Space! You can try my app on HF space here

Step Four: Embed Hugging Face to a website built from Github Page
Host a website from Github Page
Github Page is a great place to host a website for free! You can create a new repo on GitHub and enable this function in Settings -> Page
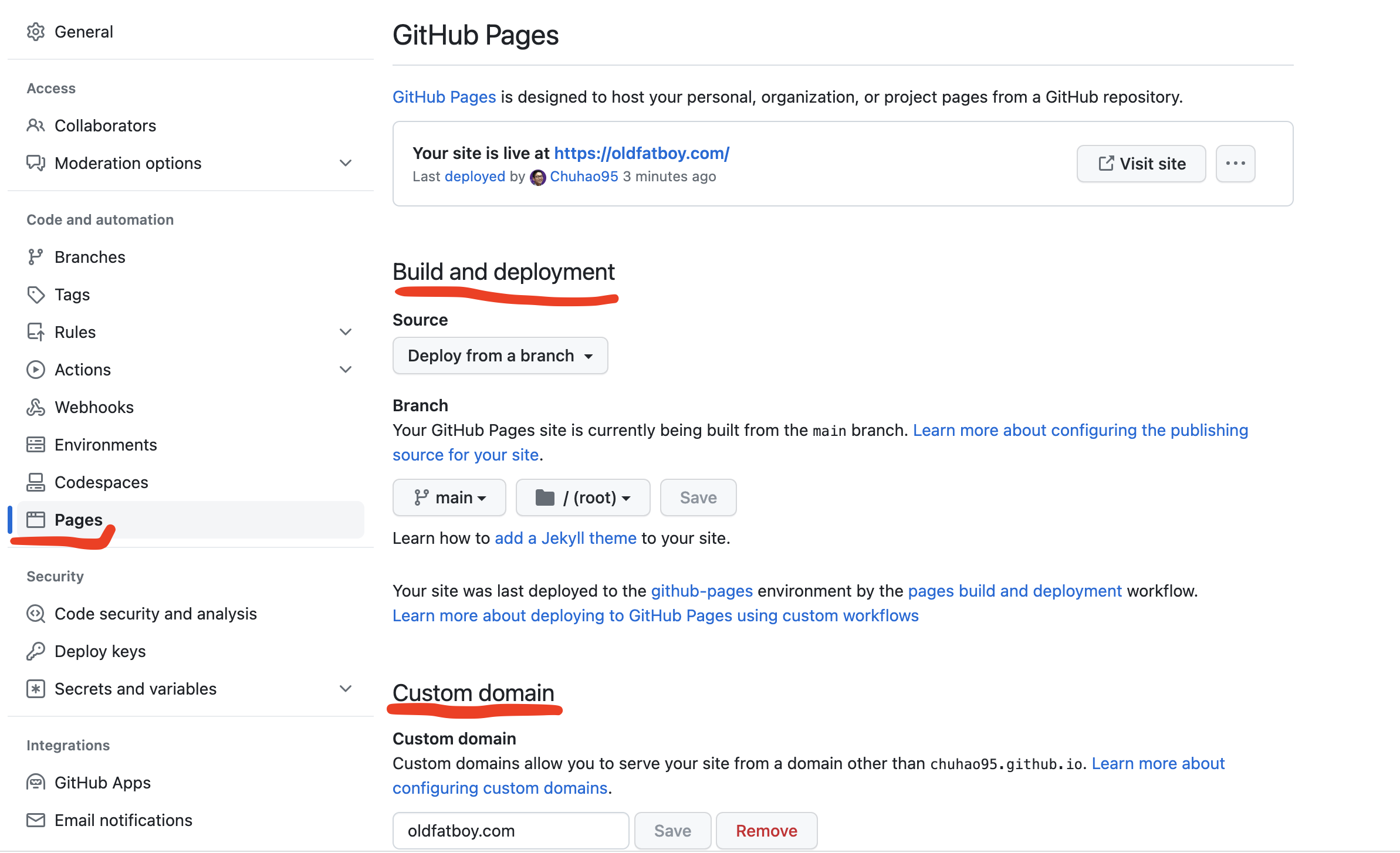
You can use a custom domain from this blog: GoDaddy Domain with GitHub Pages.
Add index.html
Add index.html to that repo.
<!DOCTYPE html>
<html lang="en">
<head>
<meta name="viewport" content="initial-scale=1, width=device-width">
<title>oldfatboy.com</title>
<style>
h1 {
text-align: center;
}
</style>
</head>
<body>
<h1>Youtube thumbnail click-thru rate predictor</h1>
</body>
</html>
Embed Hugging Face Space
Copy the embed web code from Hugging Face and paste it into the index.html inside <body> section below <h1>Youtube thumbnail click-thru rate predictor</h1>.
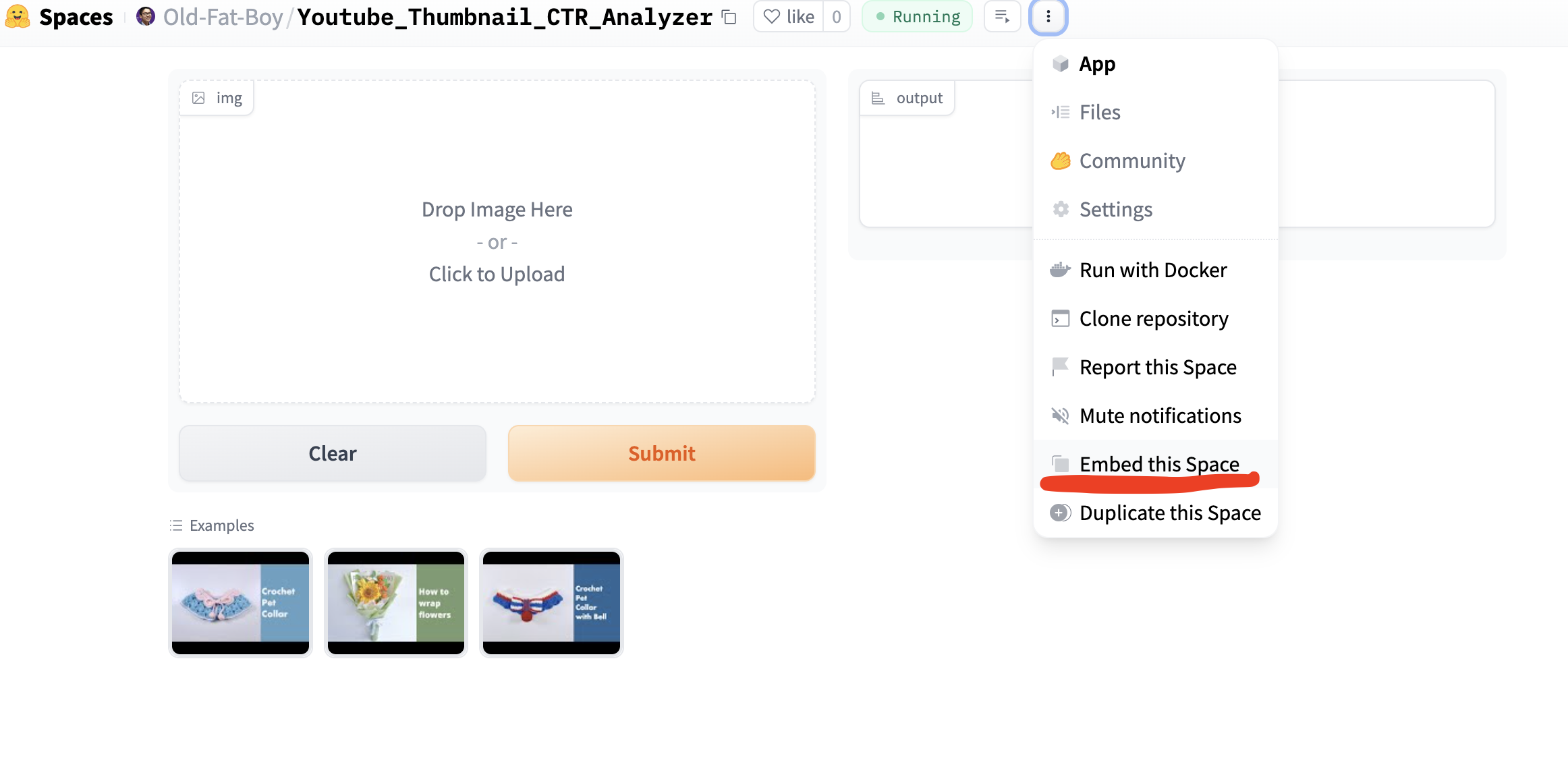
For example, my embed web code is:
<script
type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/3.37.0/gradio.js"
></script>
<gradio-app src="https://old-fat-boy-youtube-thumbnail-ctr-analyzer.hf.space"></gradio-app>
I copied it twice into my index.html so my wife could compare two photos same time.
Thanks for reading! Happy coding! Thanks for fast.ai to teach me all of these. So I can share it with you! Also thanks to Simon Kubica for reviewing it.